TARDIS-Pose: Targeted Distillation of Self-Supervised ViT features for Animal Pose Estimation
Abstract
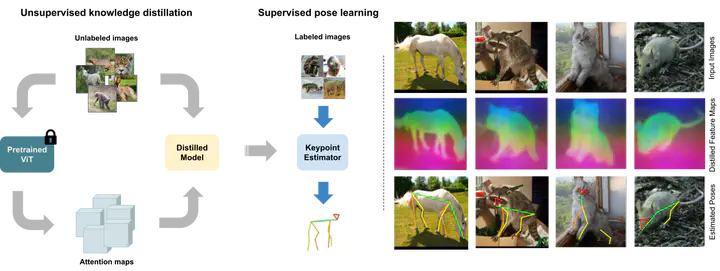
Animal pose estimation is an important ingredient of many real-world applications in behavior monitoring, agriculture, and wildlife conservation. At the same time it is a highly challenging subject as annotated datasets are scarce and noisy, and variability both within and across animal species in pose and appearance is significant. Here, we propose a novel framework addressing these challenges via distillation of self-supervised vision transformer (DINOv2) features. These features are extracted in a first stage on unlabeled data to produce an image-based attention map. An image encoder-decoder network is next used to predict these attention maps through distillation via supervised training. During this stage, augmentation is employed to enhance robustness across changes in viewing conditions. To learn keypoint locations, we remove the decoder part of the distilled network and train a new heatmap decoder that uses the same inputs to predict location heatmaps. The final keypoint prediction is done via the distilled image encoder and the heatmap decoder. Using this targeted distillation approach, we achieve new state-of-the-art results on AP-10K and TigDog datasets especially in zero-shot and few-shot settings, but also for fully-supervised training.