Björn Browatzki
Computer Vision Researcher
Machine/Deep Learning Engineer
Hi there, I’m Björn (비연). I’m a computer scientist and engineer. I create software to perceive and understand the world around us.
During my PhD at the MPI in Tübingen, I developed multimodal object perception skills for robots in collaboration with the IIT in Genoa and Fraunhofer IPA. Later, I joined the interactive video startup Wirewax in London where I had the pleasure to work on many fun computer vision problems including Face Identification, Nudity Detection 👀 and Object Tracking.
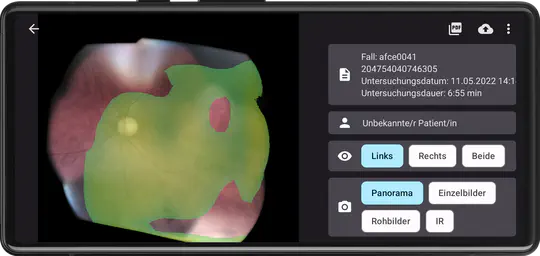
In 2018, I moved to Seoul for a position at Korea University. My work mostly revolved around decoding, encoding, recoding, and analysing large amounts of facial data. At that time, I also started with the analysis of retinal images. This project eventually turned into eye2you GmbH, a medtech startup that was set out to create a smart and portable fundus camera for a wide range of medical applications.
I have a particular interest in few-shot settings and semi-supervised approaches using unsupervised generative methods.
Finally, I’m also a running enthusiast (=addict). Whenever I can, I’ll be somewhere on a track or on a trail.
🔹 Spaces over tabs 🔹 VI over Emacs 🔹 C++ over Java 🔹 Light mode over dark mode
- Faces, Eyes, Bodies
- Medical AI
- Robotic Vision
PhD (Dr.-Ing.) in Computer Vision, 2014
Max Planck Institute for Biological Cybernetics
MSc (Dipl.-Inf.) in Software Engineering, 2009
University of Stuttgart
Projects

Publications
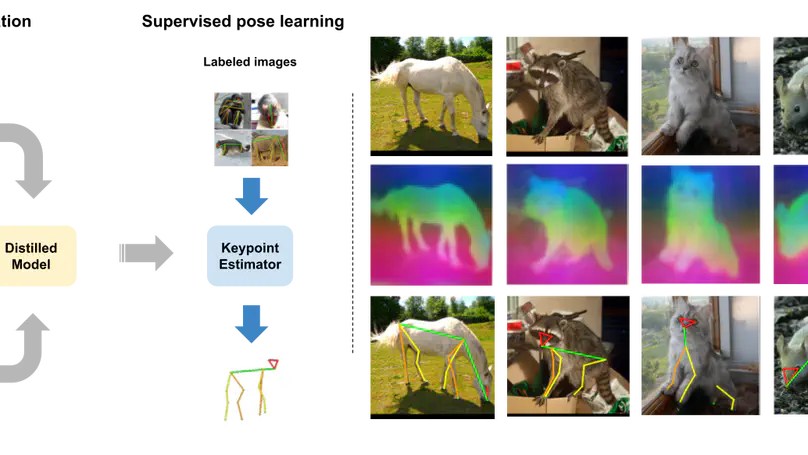


Current supervised methods for facial landmark detection require a large amount of training data and may suffer from overfitting to specific datasets due to the massive number of parameters. […]

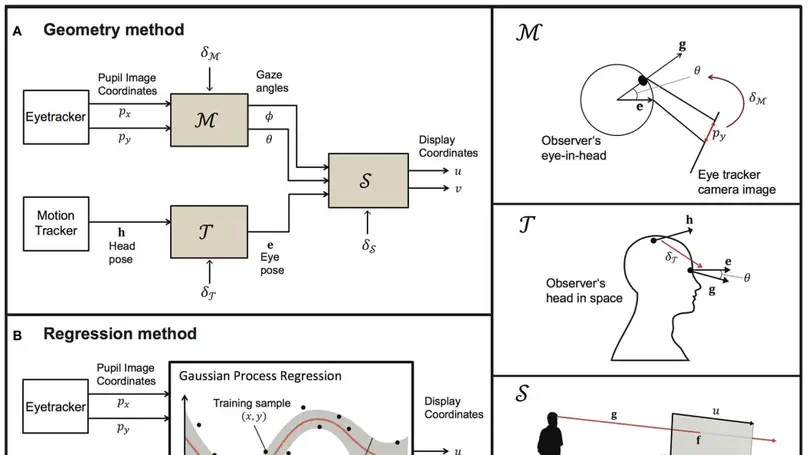
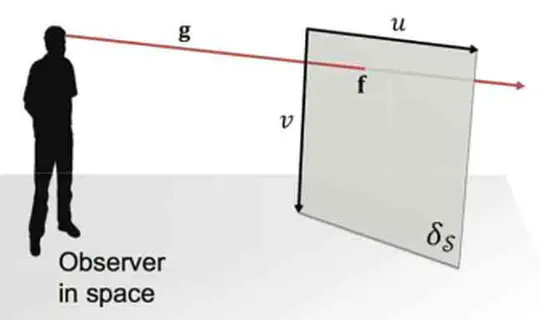
Contact Me
- Tübingen, Germany