3FabRec: Fast Few-Shot Face Alignment by Reconstruction

Abstract
Current supervised methods for facial landmark detection require a large amount of training data and may suffer from overfitting to specific datasets due to the massive number of parameters. We introduce a semi-supervised method in which the crucial idea is to first generate implicit face knowledge from the large amounts of unlabeled images of faces available today. In a first, completely unsupervised stage, we train an adversarial autoencoder to reconstruct faces via a low-dimensional face embedding. In a second, supervised stage, we interleave the decoder with transfer layers to retask the generation of color images to the prediction of landmark heatmaps. Our framework (3FabRec) achieves state-of-the-art performance on several common benchmarks and, most importantly, is able to maintain impressive accuracy on extremely small training sets down to as few as 10 images. As the interleaved layers only add a low amount of parameters to the decoder, inference runs at several hundred FPS on a GPU.
Conference Talk (5min)
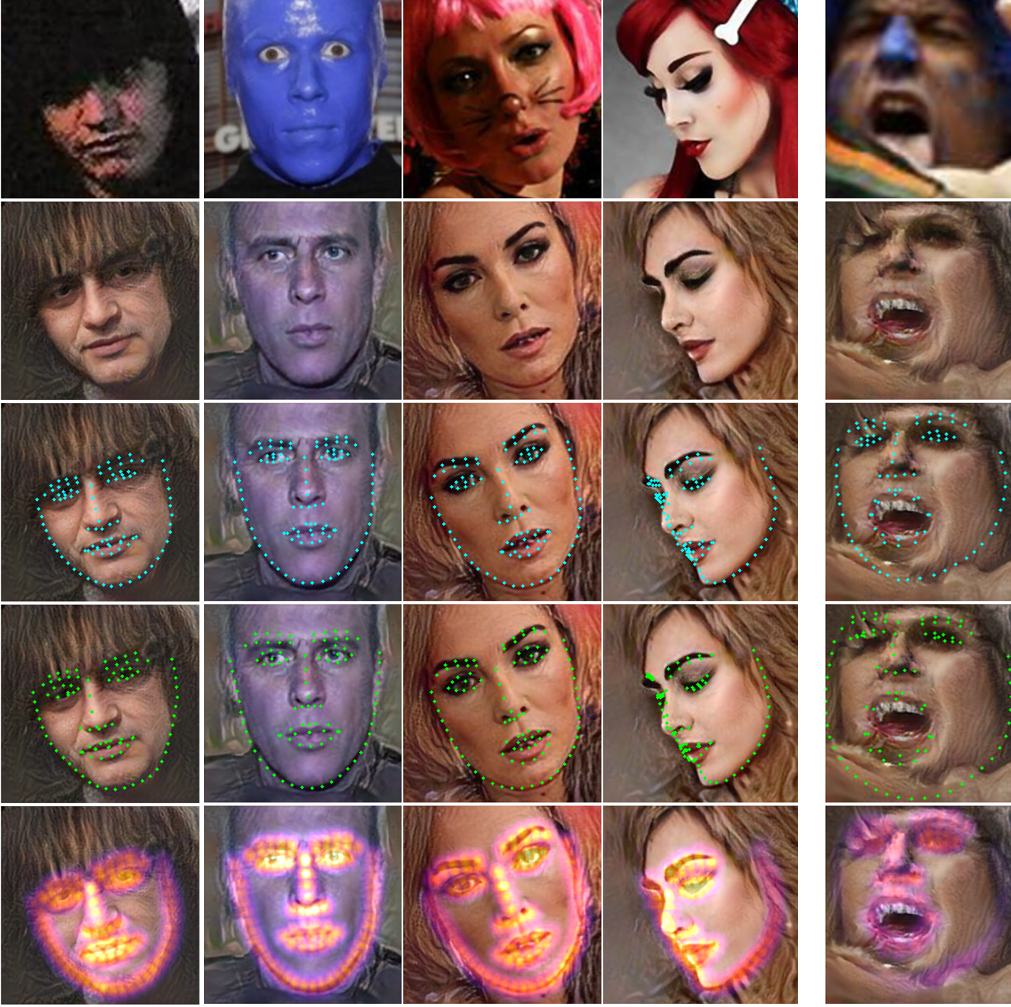
A few examples
Rows show the original, and the reconstruction itself, with predicted landmarks, with ground-truth landmarks, and with predicted landmark heatmaps, respectively.
The fifth column illustrates a failure case.